
クラスタという言葉そのものには聞き覚えがあるかもしれません。
でも、中身はよく知らないな。
横文字だし難しそうだな〜という印象をお持ちではないでしょうか?
そこで今回は、簡単な例でクラスタリングについて説明していきます。
結論
- クラスタリングとはグループ化することです。
- 似た特徴を持つデータをまとめ、複数のグループに分けてくれます。
- ビッグデータを人間が理解できる特徴に分類し、判断や、意思決定を助けてくれます。
- マーケティングから不正検知まで、様々なシーンで活躍する考え方です。
クラスタリング とは
クラスタというのは、グループを意味しています。
つまり、クラスタリングとは、グループ化です。
これをデータ分析的にいうと、たくさんあるデータからそれぞれのデータを似た特徴を持つもの同士で複数のグループに分けるということになります。
似た特徴同士って
では、どのようにして、似た特徴をもつもの同士の組み合わせを作るのでしょう?
今回は購買回数と購買金額に関するお客さまのデータを使って、似た特徴のお客さま同士で、いくつかのグループに分けることを目指します。

今回の例は購買回数と購買金額の2つの変数なので、散布図で、わかりやすく見ることができます。
X軸に購買回数を、Y軸に購買金額として散布図をプロットしてみましょう。
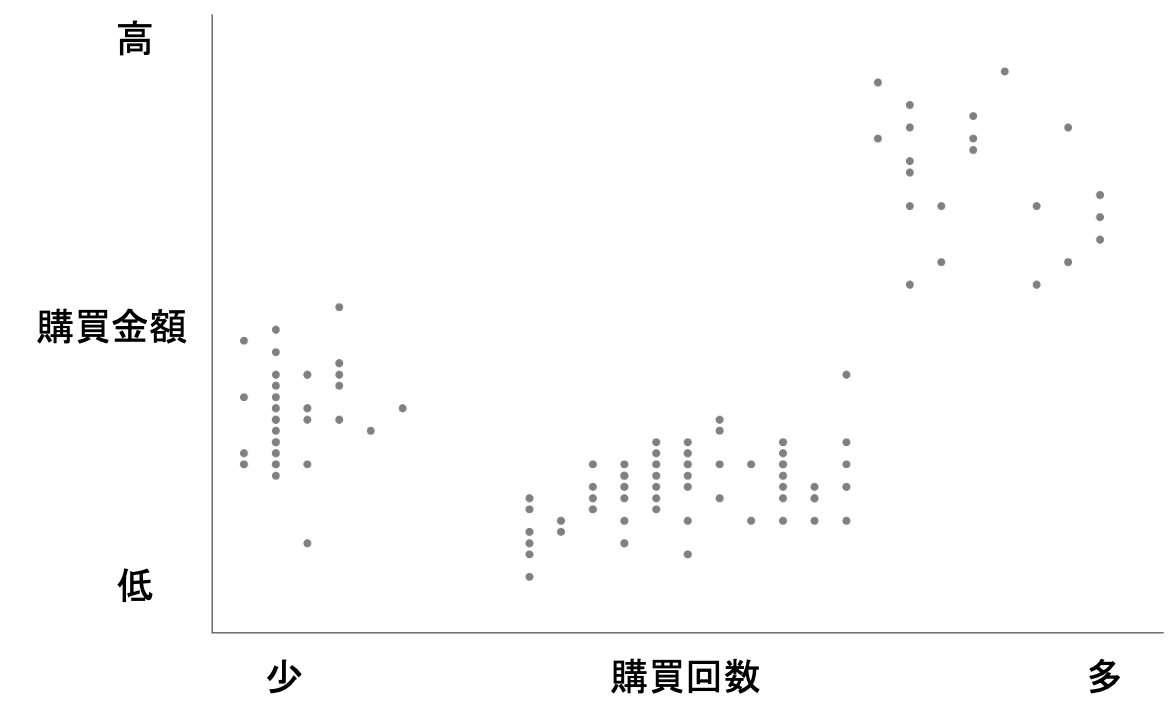
散布図によってこのデータは3つのグループに分かれそうだな、と思いますよね。

視覚的に点同士の近さによって、グループが作れそうですよね。
もうお分かりだと思いますが、似たもの同士と判断するためには、比較するもの同士の距離が大事なのです。
では距離の計算について次の例を見ていきましょう。
Aさんは、BさんとCさんどちらに近いでしょうか。

これは中学校で習う三平方の定理を使うことによってできます。

これをAさんとCさんの距離も計算して比較すると、どちらに近いかというのがわかります。クラスタリングでは、このような計算をあらゆる組み合わせで実施し得られた距離の比較によって、近いもの同士をグループ化することができるのです。
また、今回は2つの変数で計算していますが、変数がたくさんあっても同様に計算が可能です。
一方で今回の例で注意しなければならないのが、購買金額、購買回数の値をそのまま使ってしまうと次のようになります。

購買回数の値が小さすぎて無視されていますね。
このようにクラスタリングをする時は、単位によるスケールの差が影響してしまいます。そのためこのスケール差を無視して適切に距離を計算できるように事前に標準化して考えます。
標準化とは、各値について平均を引いて標準偏差で割るという処理を加えることです。
これによって平均0分散1のデータの集まりとなり、単位が異なるデータの集まりであっても、比較ができるようになります。
※解析方法によっては機能がないかもしれないので、予めデータを標準化しておきましょう。
どんなことに使えるの?
まず、今回の例のような顧客分析があります。
売上や利益に貢献しているお客さまの特徴と、そうではないお客さまの特徴をグループに分けて作戦する「顧客セグメント」は代表的な使いみちです。
またRFM分析と併用すると、非常に効果的です。
RFM分析によって顧客ごとのRFMを算出後、RFMをもとにクラスタリングを実施するだけで、即座に重要顧客がグループ分け出来ます。
市場分析として顧客の属性(性別、年齢、住所、職業等)をグループ化したり、過去にどんな商品やカテゴリを好んで買っているかを基にグループ化するなど、マーケティングの判断材料として様々なシーンに使えます。
マーケティング以外の活用方法として、例に挙げたいのが「不正検知」です。
似た特徴のもの同士をグループにするということは、裏を返せば、明らかに特徴の違うもの同士を分けることにも使えるのです(結構大事)。
例えば、不正な取引と正常な取引は、明らかに特徴が違うものなので、それを区別する方法として、クラスタリングは効果的です。
このように、クラスタリングは、データ全体に、どのように特徴的なグループがあるのか、人間が理解しやすいシンプルさで明らかにしてくれます。
データの規模が大きすぎて、判断に使うのが難しいビッグデータであっても、人間に理解しやすく整理してくれるため、データに基づく意思決定を助けてくれるのです。
まとめ
クラスタリングは、データを理解し、人間がそこから意思決定したり、判断するのを助けてくれます。
今回は、マーケティングから、不正検知まで、あらゆるシーンでクラスタリングが活用できることをご紹介しました。
是非ともモノにしたい手法ですね。
かっこの「さきがけKPI」は、ローコスト、短納期で、クラスタリング分析をお手伝いすることもできますので、ぜひ、ご相談ください。







